PinnedJonathan HuiA listing of my articles in deep learningIncludes object detection, self-driving car, meta-learning etc …Apr 19, 201813Apr 19, 201813
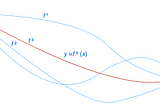
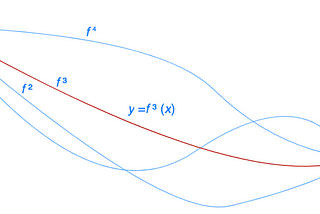
Jonathan HuiOptimization: Calculus of VariationsTo find the optimal values of a function f, we solve for the points where its derivative f’ equals zero.Jul 3Jul 3
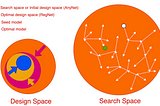
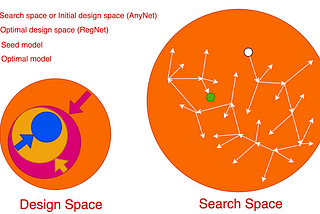
Jonathan HuiRegNetNAS-like methods explore a search space to find optimal models for specific tasks. In contrast, RegNets take a systematic approach by…Jun 10Jun 10
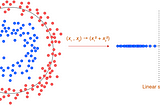
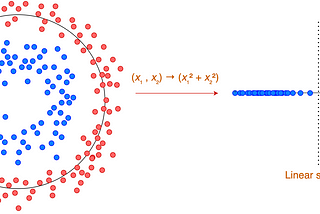
Jonathan HuiKernels for Machine LearningIn many machine learning problems, input data is transformed into a higher-dimensional feature space using a non-linear mapping to make it…May 274May 274
Jonathan HuiVector Space, Normed Space & Hilbert Space (Machine Learning)Euclidean space, the familiar geometry of our everyday world, provides a useful framework for understanding basic geometric concepts like…May 204May 204
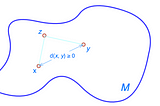
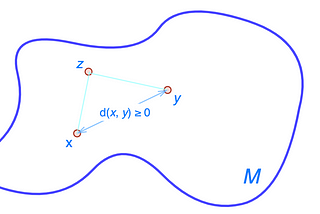
Jonathan HuiThe Study of Mathematical Spaces (Machine Learning)The terminology of mathematical spaces in AI research papers can be intimidating. Fortunately, understanding these concepts isn’t always…May 154May 154
Jonathan HuiWhat is new with GPT-4?On March 14th, GPT-4 was released. It gave us some insight into its progress toward achieving superhuman proficiency. Nonetheless, you may…Mar 15, 20231Mar 15, 20231