Detect AI-generated Images & Deepfakes (Part 2)

Deepfakes has gained tremendous traction because many easy-to-use free software packages are available which require no AI experience. If you know basic video editing and have a decent graphics card, you can pick up the skills and produce good quality videos easily. Nevertheless, there are other technologies that produce fake videos that are potentially harder to detect. We will cover some of the concepts in Part 2 here.
While Deepfakes adopt a Deep Learning centric approach, other technologies may integrate domain knowledge in 3-D facial manipulation, VR and warping in fabricating the videos. In addition, if you can fabricate the new content using the frames in the original video, it can reduce issues related to illumination, skin-tone, etc … Also, the fewer chances you made the less likely to be detected. In many cases, these frames are manipulated and/or re-rendered to lip-sync with the newly fabricated audios. The most active changes are usually localized in the mouth areas.
Throughout the article, we will provide high-level technical discussions also. Nevertheless, feel free to skip them according to your interest level and refer to the research papers if you need more specifics.
RecycleGAN
One popular application of GAN is transforming images from one domain to another. For example, we can create generators to transform real images into Van Gogh style paintings. To accomplish that, by feed real and created images separately, CycleGAN trains a discriminator to criticize how the generated images are doing compared with the real Van Gogh paintings. On the other hand, these secrets will also propagate to the generators to create better images. The objective is to train both the discriminator and the generator alternatively so they keep helping each other. Eventually, the generator will be improved to recreate Van Gogh style paintings from any real pictures.

RecycleGAN extends this concept in CycleGAN further in producing video. First, it makes sure each generated frame will inherit the “style” of the target domain. But that is not enough. RecycleGAN also promotes a smooth transition between consecutive frames for temporal coherence also. This eliminates or reduces the flicking in the videos. Here is a demonstration video.
As a side note, Deepfakes is often mistaken as a GAN technology. Indeed, the majority of the implementation is not GAN related. Nevertheless, as the resolution increases, I do feel that GAN can help in producing better fidelity images in videos similar to what StyleGAN2 may achieve. Some of the implementations starting adding GAN models. But this is still early and in specific, GAN is very hard to train.
RecycleGAN Design (optional)
Let’s start from Deepfakes’ loss function and see how such temporal coherence is achieved. The loss function for Deepfakes’ encoder and decoder minimizes the reconstruction loss.

(The equations in this section are originated or modified from this source.)
In GAN, the objective function is a min-max game which makes both discriminator and generator better alternatively.
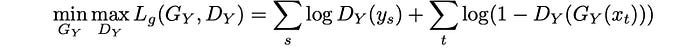
Now, the goal for RecycleGAN is to add a loss function that the generated frames belong to domain Y (spatial consistency) while maintains temporal coherence.
Now, let’s say P is a temporal predictor (a.k.a. a generator) that predicts video frames from all the previous frames. To train this predictor, RecycleGAN minimizes the recurrent loss which compares the predicted frames with the original.
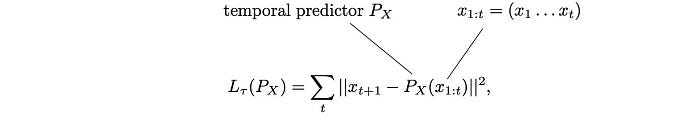
Let say Gy(xᵢ) is the generator to transform the frame xᵢ into yᵢ. We can introduce another loss function called recycle loss defined as:
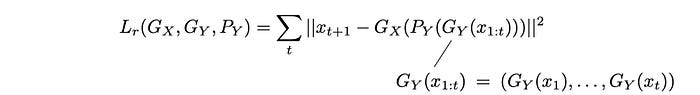
It calculates the reconstruction loss using the generator and the predictor in creating images. This loss function enforces both spatial and temporal coherence.
The final loss function for RecycleGAN includes the objective function in GAN, the recycle loss and the recurrent loss.
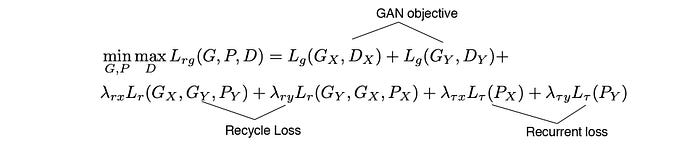
Face2Face
Face2Face transfers the facial expression of the source actor (the top actor) to a target actor (Donald Trump). For example, if the source actor opens his mouth, Face2Face will reenact the same expression on the target video.
Face2Face Design (optional)
Trained with video sequences, Face2Face models a PCA model to represent a face in a video frame with a low-dimensional latent space. Under this model, this face will be parameterized by the face model parameters including geometric shape, skin reflectance, and facial expression. The first two factors identify a person while the expressions change in different frames.
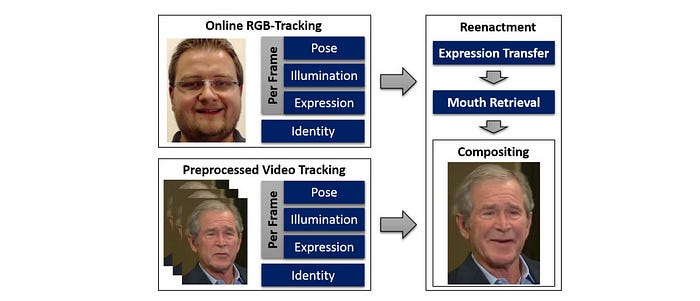
In runtime, Face2Face models the facial expressions of both the source and the target video frames using the face expression parameters. Next, it performs a deformation transfer in this expression parameter subspace between the source and the target. This transformation changes the expression factors of the target to reenact the source actor’s expression.
Afterward, Face2Face renders the target synthesized face using these transferred expression coefficients in conjunction with the parameters in the target video: the rest of the face model parameters, the estimated environment illumination, and the pose information. The camera parameters will also be used.
In addition, to synthesize a realistic target mouth region, Face2Face searches through the target video sequence to find the mouth interior that matches the re-targeted expression the most. However, some compromise will be made between the previous mouth frame and this most matched frame to enforce temporal coherence. Technically, it finds the frame of the training sequence that minimizes the sum of the edge weights to the last retrieved and current target frame in an appearance graph. There is a lot of details missing here on this graph. Please refer to the research paper if needed.
Finally, it composites the new output frame by alpha blending between the original video frame, the mouth frame, and the rendered face model.
Learning Lip Sync from Audio
Given a video and an independent audio clip, can we re-render the mouth area of the video to match the audio? If this can be done, this is quite a danger. For example, someone can impersonate a fraudulent audio script and make it seems legit on a real video.
For this section, we will discuss lip-syncing technology done at the University of Washington. The diagram below is the workflow. It substitutes the audio of a weekly presidential address with another audio (input audio). In the process, it re-synthesizes the mouth, the cheek, and the chin area so its movement is in-sync with the fake audio.
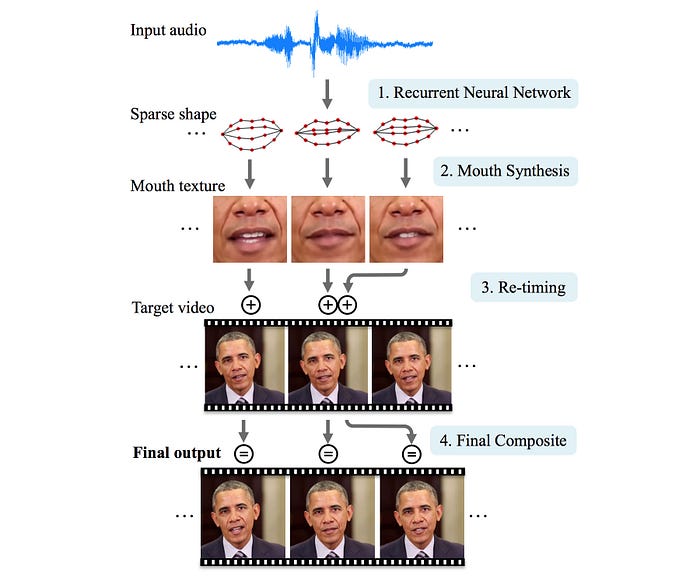
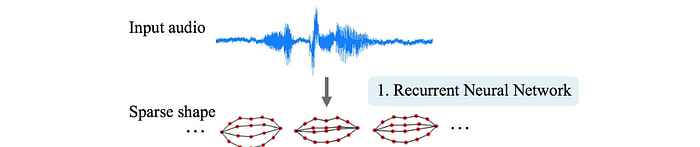
Lip Sync from Audio Design (Optional)
First, given input audio of Obama, it uses an LSTM network to model the 18-point mouth landmarks.
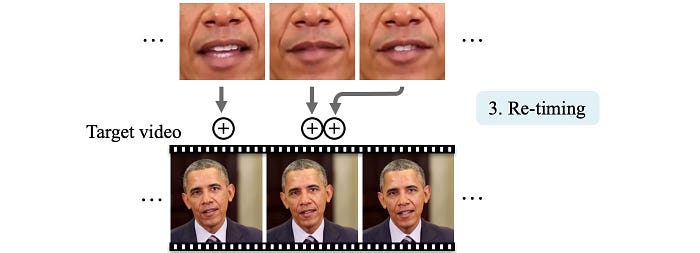
With these landmarks, it synthesizes texture for the mouth and lower region of the face (details later). Then, it will re-times where the new mouth texture should merge with the target video. For example, Obama usually stops the head movement when pausing a speech. Such re-alignment will make the head movement more natural and in-sync with the lip motion. Finally, it composes everything together.
Let’s get into more details. The audio will be represented with MFCC coefficients that heavily used for speech recognition.
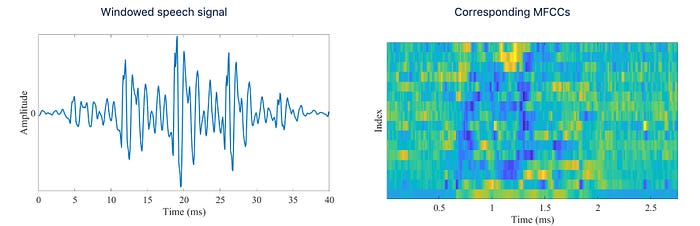
The shape of the mouth is represented by 18-point mouth landmarks below. With many hours of Obama’s weekly address footage, it trains an LSTM to take a sequence of MFCC coefficients and output a sequence of the mouth landmarks.

Next, we are going to synthesize the lower part of the face below based on these landmarks.

For each video frame in the target video, it rebuilds a 3-D model for the face programmatically and derives the corresponding mouth shape.

Then, n frames that have the smallest L2 distance between the frame’s mouth shape and the target mouth shape are selected. The value of n will be selected carefully as the temporal coherence will improve as n is increased, but the image fidelity will drop. Then the mouth texture above is computed as a weighted median per pixel from these n frames in which the weights are related to how close the mouth shapes are between the selected frame and the target video.
As quoted from the paper,
Synthesizing realistic teeth is surprisingly challenging. The teeth must appear rigid, sharp, pose aligned, lit correctly, and properly occluded by the lip.
To improve the teeth area, it combines low-frequencies from the weighted median texture and high-frequency detail from the teeth in the target video. Then it is sharpened to improve the teeth rendering.

Also, the head movement changes with the speech. For example, when Obama pauses his speech, his head and eyebrows will stop moving. The head movement of the target video will not align with the new mouth texture which is aligned with the new speech. To solve this, the mouth texture will realign with the target video according to the head movement. For example, it will prefer no head movement when the audio is silent.
Then, it applies further warping to improve the jawline blending of the lower face texture with the target head. As shown below, the second Obama’s picture has the jawline improved without the double edge.

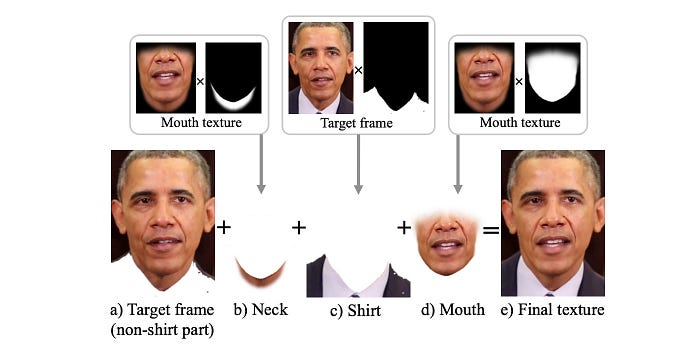
Based on the target video and the synthesized mouth texture, it generates layers (a) to (d) below and uses the Laplacian pyramid method to blend them together.
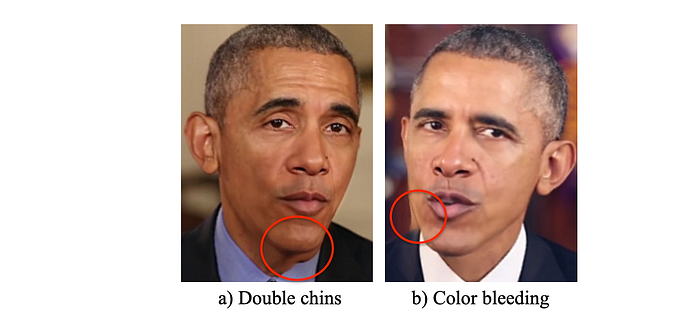
This method mitigates some artifacts including double chin and color bleeding in the chin area.
The top row below is the video for the input audio and the second row is the fabricated video.

Text-based Editing of Talking-head Video
“The Dow Jones drops one hundred and fifty points” is very different from “The Dow Jones drops two thousand and twenty points” as the latter may trigger a panic selloff. In the Text-based Editing of Talking-head Video paper, by simply editing the original script in a text editor, the video will be altered visually in matching the newly edited speech content.
Here is a demonstration video.
Text-based Editing of Talking-head Video Design (optional)
The system takes the original input video and the edited text script as input.

Step ① Phoneme Alignment:
The alignment step divides a video into segments with phoneme labels, and their start times and the end times. The phoneme for the word “people” is “/ˈpēpəl/”. This tells us how to pronounce a word.
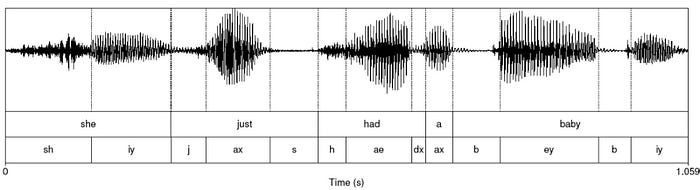
The audio is assumed to be labeled with an accurate text transcript. The remaining task is to detect the duration of each phoneme with automatic phonetic alignment software. These segments build up a library of visual clips that later, reconstruct the speaking face indirectly.
Step ② 3D Face Tracking and Reconstruction:
From each video frame, it extracts a 3-D parametric face model (geometry, pose, reflectance, expression, and illumination). From a high-level perspective, it later finds the best-matched clips for the new sequence of phonemes and merges them with the extracted face models.
Step ③ Viseme Search:
The goal in Viseme Search is to find matching sequences of phonemes in the video that can be combined to reproduce a video in mimicking the edited script’s audio. This assumes identical phonemes in a video produces similar visuals. So given an edited text sequence of words W, the goal is to find best-matching subsequences in the original video with the same phonemes and a way to best combine them to match the edited script. In the example below, W is split to W₁ and W₂ (we will not detail here on how to find the optimized split). For each split (W₁ or W₂), it locates where the original video may contain the same sequence of phonemes.
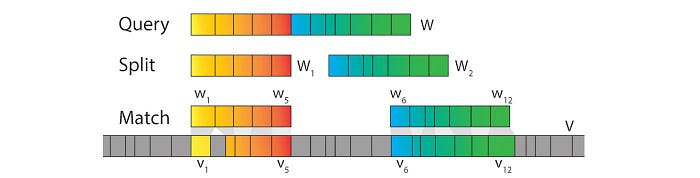
Also, the duration of the phonemes (Query) will be determined by a speech synthesizer.
Step ④ Parameter Retiming & Blending:
Nevertheless, there are two problems with this approach. In finding the matching sequence, the duration of phonemes is not considered and they are unlikely the same. Also, the transition between the matched sequences (between W₁ and W₂) will not be smooth.
Background retiming: It selects a large enough region around the edited word area and extracts the original video segment. Then it is retimed to match the duration of the new audio subsegments. To accomplish that, new frames will be resampled using the nearest-neighbor from the original frames to create a video length that matches the new audio length with duration computed by the speech synthesizer. We will call this the retimed background sequence. Below is an example of such a sequence. Since frames are extracted from different parts of the video, it may have different head sizes and postures. This will create flicking.

Next, a subsequence retiming is done such that the duration of the matched segments will also have the same length as the audio segments (the retiming/mapping is shown in the first row below).
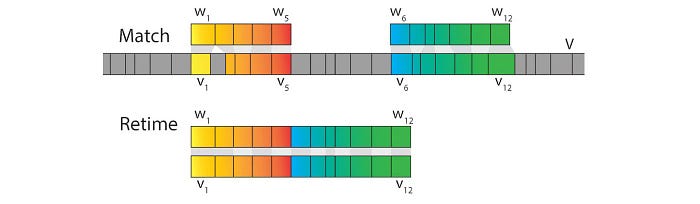
i.e. the first step transforms the segment in the original video to have the same length as W. The second step transforms the matched segments to have the same length as W too.
Parameter blending: The 3-D parametric face model includes geometry, reflectance, illumination, pose, and expression. Now, we need to create a new model that blends the retimed background sequence and the retimed matching segments together. Let’s decide what face model parameter will be kept from the background sequence first.
- The geometry and reflectance are unique to a person and will be kept constant.
- The scene illumination is linearly interpolated before and after the scene of the edited segment. This reduces the flicking in illumination.
- The head pose is modeled from the retimed background sequence.
- The final factor is the expression which composes of 64 parameters that hold information on the mouth and face movement. These parameters will be extracted from the retimed matched segments. However, to avoid flicking and to produce a smooth transition between frames, linear interpolation is done in a region of 67 ms around the frame transition.
For this step, it produces a parameter sequence that describes the new desired facial motion and the retimed background sequence.
Step ⑤ Neural Face Rendering:
Next, it masks out the lower face region in the retimed background video and renders a new synthetic lower face using the blended facial model. This results in composites rᵢ as an intermediate video representation. Then, this representation will be passed to an RNN network to reconstruct the final video sequence. The frames with the black boundary on the lower face are rᵢ. The corresponding frame on the right is the synthesized frame produced by RNN.

This RNN model is trained per person for each input video. The model will be trained with rᵢ generated from the original sequence rather than the matched sequence. The training uses objectives similar to GAN which tries to reconstruct a sequence that cannot be distinguished from the real one.
Few-Shot Adversarial Learning of Realistic Neural Talking Head Models
Given a target video (driving sequence), can it be re-rendered with style coming from other source images (top row)? For example, the resulting video will retain the same head movement but the face and the clothing will mimic the source of the same or a different person. In addition, the resulting video should be learned from as few images as possible, 8 source images in this case or less. This follows the goal of few-shot learning or transfer-learning.
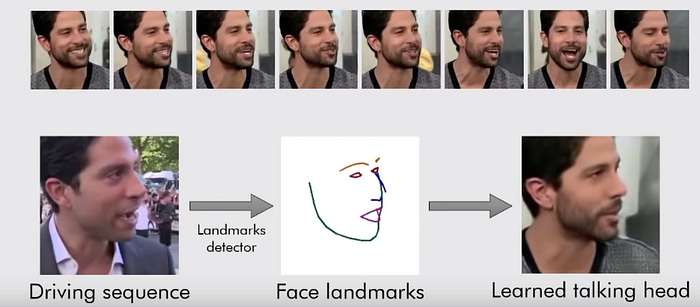
In the example below, it transfers the style of another person to a target in generating an image. First, the face landscape is extracted from the target programmatically using off-the-shelf software. Then, the landmarks are re-rendered with style coming from a source domain. In this example, only a single source image is provided (one-shot learning).
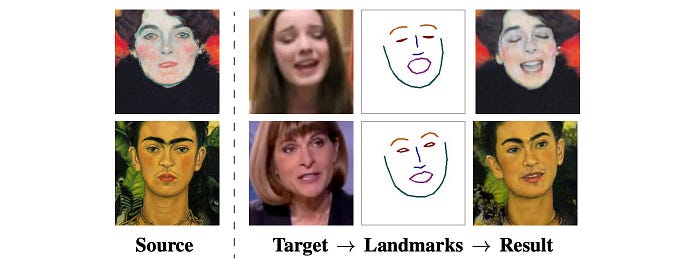
Here is the demonstration video.
Few-Shot Adversarial Learning of Realistic Neural Talking Head Models Design (Optional)
The training is composed of two stages. The meta-learning stage is trained with video sequences from different persons. Then, the fine-tuning stage will be trained with a few images (few-shot learning) to generate video sequences for a specific person, one that not present in the meta-learning stage.
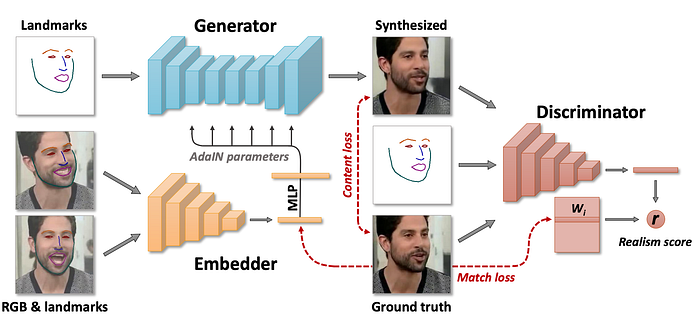
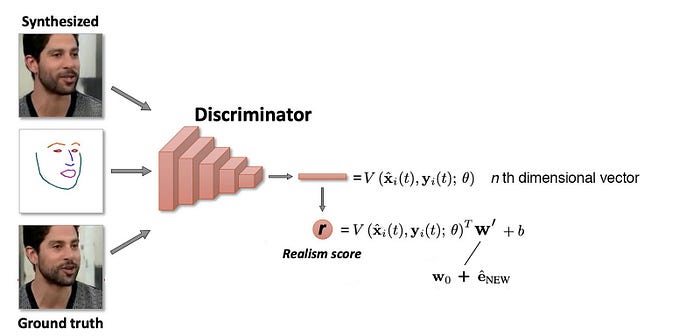
The embedder takes in an image with a face landmark detected from off-the-shelf software and generates an N-dimensional vector e. In the meta-learning stage, K frames are randomly drawn from a video sequence and feed into the embedder individually. Then, it computes its average

This vector encodes the video-specific information including the personal identity which is supposed to be invariant to the pose or a specific frame.
Next, it samples another video frame in the same video and extracts the face landscapes. This is feed into the generator in conjunction with the averaged e computed above to synthesize the image. The objective here for the generator is to create images that match the ground truth perceptually.
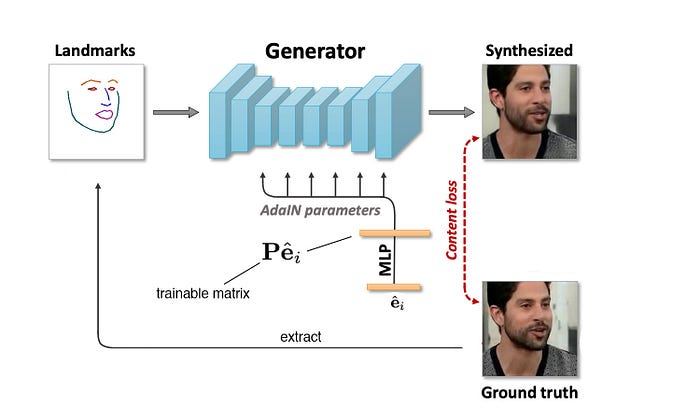
To generate the image correctly from the simple face landmarks, it multiples e with a trainable projection matrix P (i.e. Pe) to learn the style information. For example, some of the styles learned maybe the skin tone or facial features. Technically, the product Pe acts as AdaIN parameters in the AdaIN operation which is defined as:

At a high-level, it applies different parts of the style information in different spatial layers to guide the pixel generation. This involves many details that can be found here. For simplicity, we will skip the discussion.
At the same time, it trains a discriminator taking an image and the associated facial landmarks as input. It also trains a vector Wᵢ for each video i which can be interpreted as the embedding representation of this video. (similar to the word embedding concept in NLP.) The discriminator multiples the CNN output vector V with this embedding value to calculate the final score r.
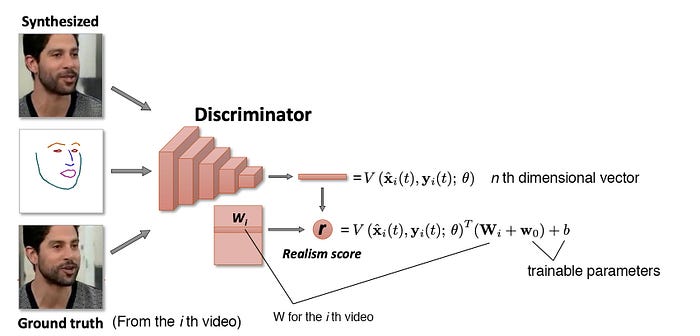
The loss function used to train the model will involve the perceptual difference between the re-generated image and the ground truth and the GAN loss. In addition, e and Wᵢ serves a similar purpose — acts as the latent factor for the ith video. Therefore, a match loss is introduced to encourage them to have similar values.

Now the model is trained to create images mimic the training videos. But to mimic a specific person, it conducts another round of fine-tuning using the images of that person. But it will enforce the few-shot training here, i.e. as few samples, say 1 to 8 images, will be provided.
First, the design of the generator will be change slightly. The input to the AdaIN operations will now be trainable and called ψ’. It will be first initialized as Pe with the new image samples.
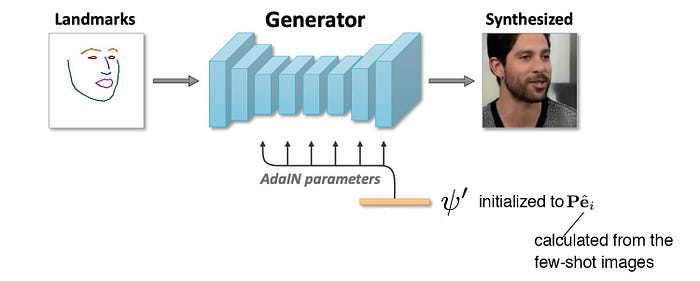
The discriminator will also replace the term Wᵢ with the sum of w₀ and e.
Audio fabrication
Many Deepfakes videos use the impersonator’s audio (the target video) for the final video. However, as demonstrated in the Stable Voices youtube channel, it can be synthesized with an AI model trained with audios of the person of interest. In particular, for some of the technologies discussed here, if an impersonator is not available for the audio, we need a voice synthesizer based on machine learning or some deep learning models. For simplicity, we will not cover this in details but some of the concepts are similar to the visual concept except the input is audio instead.
Deep Video Portraits
We have introduced many technologies in creating videos. There are plenty of them but we cannot mention all here. For the remaining sections, we will present a few more without the technical details.
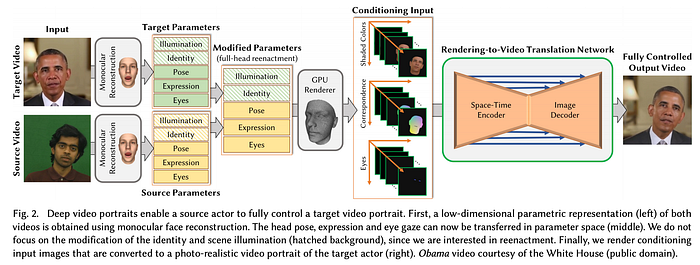
In Deep Video Portraits, it transfers the head pose and movement, facial expression, and eye motion of a source actor and enacts that on a target actor.
Deep Video Portraits Design (Optional)
Computational Video Editing for Dialogue-Driven Scenes
Everybody Dance Now
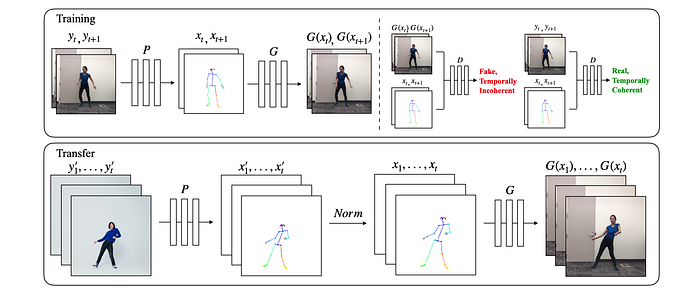
So far, we reenact a person's face or voice or a target video. But as shown below, we can reenact the pose of a source actor to a target actor. For example, we can make a novice dancer dances like a pro.
Here is the model that utilizes GAN’s concept.
Next
Next, we will look into how Deepfakes videos are created by professional.
Credits & References
Recycle-GAN: Unsupervised Video Retargeting
Few-Shot Adversarial Learning of Realistic Neural Talking Head Models
Face2Face: Real-time Face Capture and Reenactment of RGB Videos
Synthesizing Obama: Learning Lip Sync from Audio
Text-based Editing of Talking-head Video
