Image segmentation with Mask R-CNN
In a previous article, we discuss the use of region based object detector like Faster R-CNN to detect objects. Instead of creating a boundary box, image segmentation groups pixels that belong to the same object. In this article, we will discuss how easy to perform image segmentation with high accuracy that mostly build on top of Faster R-CNN.
Faster R-CNN
Let’s do a quick recap on Faster R-CNN.

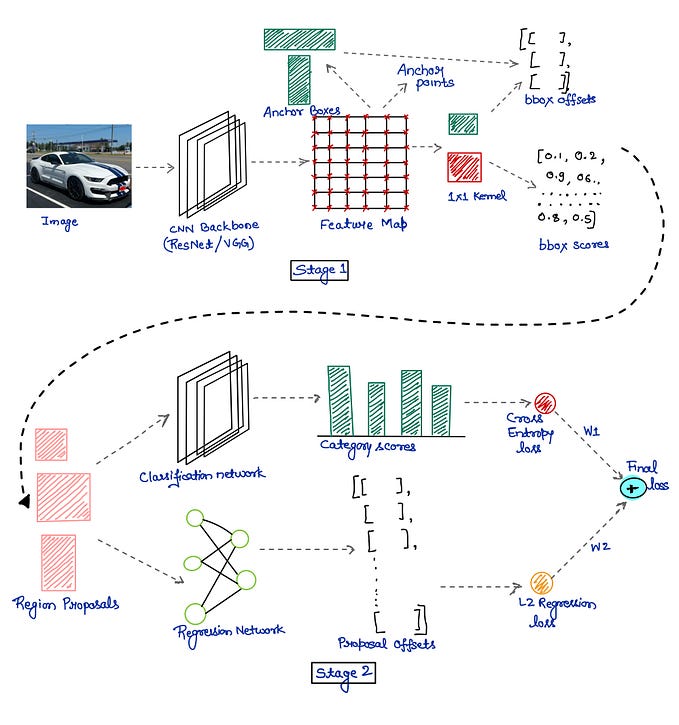
Faster R-CNN uses a CNN feature extractor to extract image features. Then it uses a CNN region proposal network to create region of interests (RoIs). We apply RoI pooling to warp them into fixed dimension. It is then feed into fully connected layers to make classification and boundary box prediction.
feature_maps = process(image)
ROIs = region_proposal(feature_maps)
for ROI in ROIs
patch = roi_pooling(feature_maps, ROI)
results = detector2(patch)If you need further introduction, please refer to this article.
Mask R-CNN
The Faster R-CNN builds all the ground works for feature extractions and ROI proposals. At first sight, performing image segmentation may require more detail analysis to colorize the image segments. By surprise, not only we can piggyback on this model, the extra work required is pretty simple. After the ROI pooling, we add 2 more convolution layers to build the mask.


The Mask R-CNN paper provides one more variant (on the right) in building such mask. But the idea is pretty simple.

ROI Align
Another major contribution of Mask R-CNN is the refinement of the ROI pooling. In ROI, the warping is digitalized (top left diagram below): the cell boundaries of the target feature map are forced to realign with the boundary of the input feature maps. Therefore, each target cells may not be in the same size (bottom left diagram). Mask R-CNN uses ROI Align which does not digitalize the boundary of the cells (top right) and make every target cell to have the same size (bottom right). It also applies interpolation to calculate the feature map values within the cell better. For example, by applying interpolation, the maximum feature value on the top left is changed from 0.8 to 0.88 now.

ROI Align makes significant improvements in the accuracy.

Mask R-CNN visualization
Let’s visualize some of the major steps in Mask R-CNN/Faster R-CNN. Using the region proposal network, we make ROI proposals. The dotted rectangles below are those proposals but, for demonstration purpose, we decide to display those that have high final scores only.

Here are the boxes after boundary box refinements when we make final classification and localization predictions. The boundary box encloses the ground truth objects better.

Just like Faster R-CNN, it performs object classification based on the ROIs (dotted lines) from RPN. The solid line is the boundary box refinements in the final predictions.

Perform the per class non-maximum suppression (nms)
It groups highly-overlapped boxes for the same class and selects the most confidence prediction only. This avoids duplicates for the same object.

Here are our top final classification and boundary box predictions from the Faster R-CNN portion.

Here are the input picture and some of the feature maps used by the RPN. The first feature map shows high activations on where the cars line up.

Some of the corner locations of the boundary boxes:

And the distributions for the offsets from the anchors:

This is top final predictions from Mask R-CNN.
Resources
Detectron: Facebook Research’s implementation of the Faster R-CNN and Mask R-CNN using Caffe2.
Mask R-CNN implementation in TensorFlow.