RL — Imitation Learning
Imitation is a key part in the human learning. In the high-tech world, if you are not an innovator, you want to be a quick follower. In reinforcement learning, we maximize the rewards for our actions. Model-based RL focuses on the model (the system dynamics) to optimize our decisions while Policy Gradient methods improve the policy for better rewards.


On the other hand, Imitation learning focuses on imitating expert demonstrations.


With the great success of the supervised learning, it is not too hard to train a policy by collecting expert demonstrations, and supervised training has better stability than many RL methods.


Challenge
One of the biggest challenges is collecting expert demonstrations. Unless it has a huge business potential, the attached cost can be prohibitive. But technically, there is another major issue. We can never duplicate things exactly. Error accumulates fast in a trajectory and put us into situations that we never deal with before.

For a human, we take corrective actions when we drift off-course. Let’s suppose we want to drive straight in an intersection. Let’s say we are slightly off-course to the left. As a human, we take corrective action to steer back to the right.

But there is a problem for the imitation learning. We have not collected any expert demonstration in this off-course situation. Or worse, the training samples may suggest us to turn left indeed. The problem behind imitation training is we don’t purposely ask experts to make mistakes so we learn how experts deal with errors. If we do that in real life, it triggers a lot of safety issues in the training.
So let’s brainstorm what can be done.
- Can we collect more training samples similar to those off-course situations?
- Can we purposely simulate off-course situations if safety is not a problem?
- Can we train the model better to reduce those off-courses?
Hacking solution
We may not want to simulate those off-course situations but that does not imply we cannot identify and record them. Let’s look at a hacking solution. The self-driving training car has three cameras. We use supervised learning to train the policy with the center camera.

But the left and right cameras are for detecting situations that we need to take corrective actions. For example, if we should go straight but see something close to the left camera, we should steer slightly to the right.
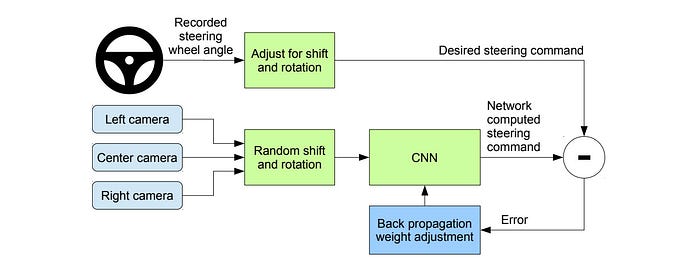
This kind of solution will work only for a specific task. The following is another example of flying drones over a forest path.
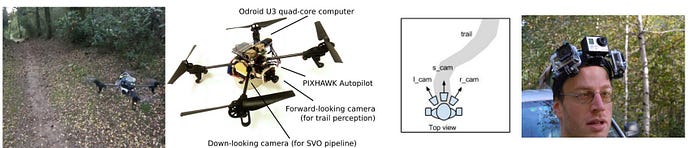
DAgger (Dataset Aggregation)
We can also collect more training samples for those off-course situations. We can run our current policy and observe. We then ask the human experts to label the possible actions again. This allows us to collect samples that we miss when we deploy the policy.

Here is the DAgger algorithm:

But be warned that this solution may require the policy to be mature enough for deployment. However, recollect training samples are expensive and human intervention in deployment is troublesome.
Stabilizing controller
In reinforcement learning, the policy (or the controller) that we run can be non-deterministic during the training. The following is a linear Gaussian controller. We use a Gaussian distribution to describe the possible action taken. The importance is our actions can vary slightly.
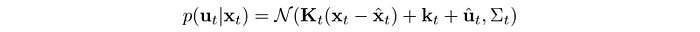

This allows exploration during training and forces the system (or the expert) to handle those slightly off-course situations. For safety reason again, this solution is more viable if it is done in a computer simulation. With model-based RL, we can replan at every time step. After making new observations of the states, we can use the trajectory optimization method to determine any corrective actions. However, we make ask why we need the imitation learning when the trajectory optimization is available. The short answer is the trajectory optimization may be good at taking corrective actions in this slightly off situation but not good at giving general instructions. There are other reasons but we will not cover it for now.
This discussion leads us to a possibility that we may ask a computer to label the actions instead of a human. As shown above and the Guided Policy Search, we can use the trajectory optimization method to provide those corrective actions. This makes the solution more financially viable.

In fact, during training, we can deploy expensive sensors to measures the states of the environment. With fancy optimization methods, this may plan actions as good as a human and provides expert trajectories for us to imitate. But for the solution to be financially viable, we need to train the second policy without those expensive sensors.

For example, our self-driving cars may have LIDAR, RADAR and video cameras during training to observe the environments. But for mass production, we may drop the LIDAR because of the cost. Here, we force the supervised training for a second policy to imitate the first policy but without the expensive sensors. Those state information needs to be extracted from the video camera directly. This is like a divide-and-conquer concept. The first policy focuses on the complex trajectory optimization using those extra states and the second one focus on the feature extraction.
Partially Observable Markov decision process

In one of the previous example, the challenge is not necessary on the missing training data. From the image above, are we trying to go left or go right? In some cases, objects may be obstructed in the current frame. Therefore, we cannot determine our action from a single frame only. We need history information. There are two possibilities to address this. In the first approach, we concatenate the last few image frames and pass it to a CNN to extract features. Alternatively, we use an RNN to record the history information as below:

Imitation Learning v.s. Reinforcement Learning
Imitation Learning requires expert demonstrations which are often supplied from human experts. But in Guided Policy Search or PLATO, it is provided by a trajectory optimization method or a system that has better access to the states. In imitation learning, we deal with drifting where no expert demonstration is available. RL is often not very stable and not easy to converge. Imitation Learning uses supervised learning which is heavily studied with more stable behavior. But the trained policy is only as good as the demonstrations.
In reinforcement learning, we need to know the rewards function directly or through observations. Its success depends heavily on how well we explore the solution space. But it has no limit on how good the policy can be.
So can we combine both together? The expert can tell us where to explore which save the RL a lot of effort? And we can apply RL to refine a policy better than a human and able to handle the off-course situations better.
Pretrain & finetune
The first approach uses the expert demonstration to initialize a policy. This jumps start the search. Then we apply RL to improve the policy and to learn how to deal with those off-course scenarios.

While RL can improve the policy, it can still produce bad decisions that make the policy worse. As more bad decisions are made, we forget what we learn from the expert demonstration.

Demonstration as off-policy data
The key problem in imitation learning is how to train the policy when we are drifting off-course. For on-policy training, we collect samples using the current policy. Since the current policy is not trained well in those off-course situations, we are making the situation worse.

But for off-policy learning, the policy gradient or the Q-values can be calculated from samples collected from other policy. In this case, they are the expert demonstrations and experience collected during the training. If the drifting is not too far away, there is a chance to reuse old samples for our optimization.
Importance Sampling with demos
For example, we use the demonstrations and experience from the training as off-policy data. Combining with importance sampling, we can use these data to estimate the expected rewards of the new policy. For example, this is the policy gradient computed from demonstrations and experience.
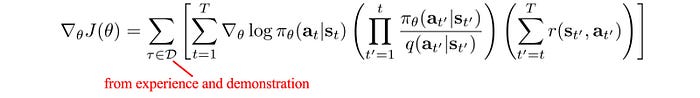
For the importance sampling estimation to have low variance, we should sample area with high rewards more frequently. i.e. the sampling distribution q should be.
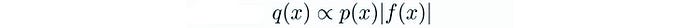
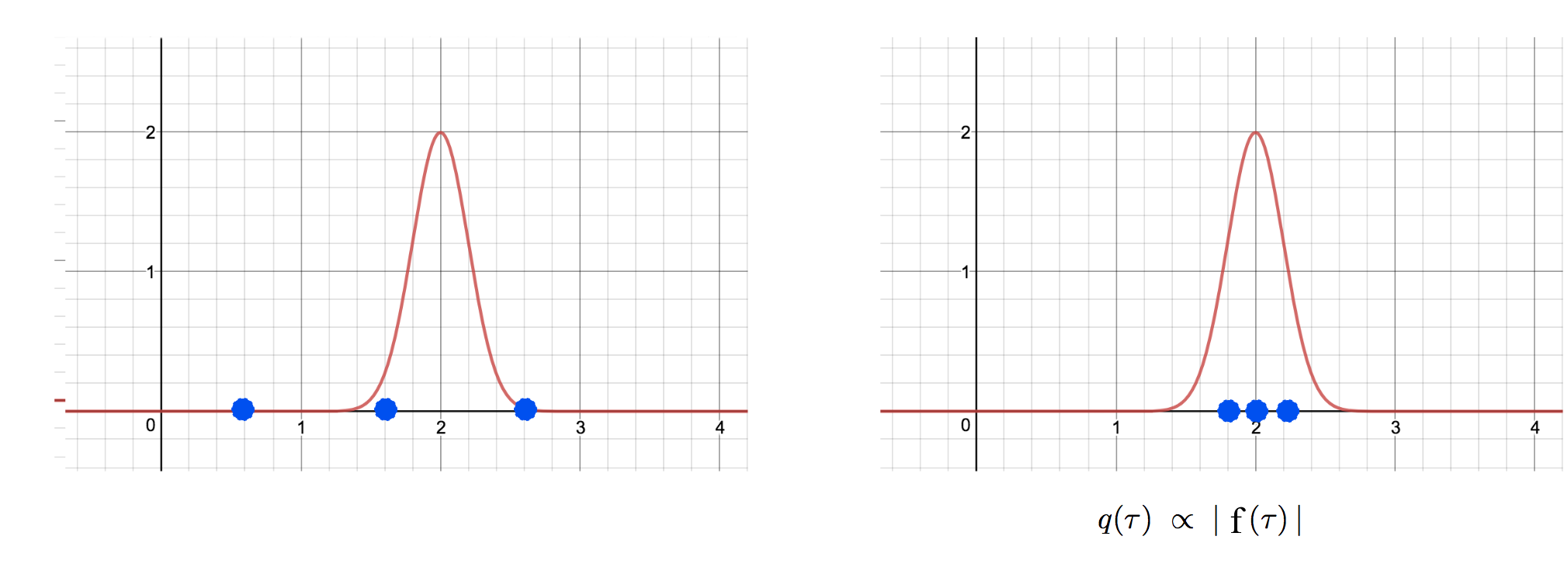
Both demonstrations and experiences should have high rewards, and therefore it is good for our policy gradient estimations. Finally, to model the probability distribution for our demonstration, we use
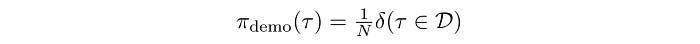
Q-learning with demonstrations
For Q-learning, this is even simpler since it uses off-policy learning already.

Hybrid objective
To take advantage of both worlds, we can also combine RL and imitation learning objective to form a new one.
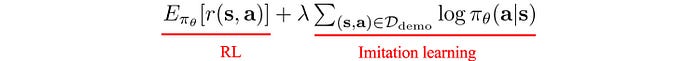
The hybrid objective would not lose the memory of the demonstrations. However, this adds more hyperparameters and the objective for the imitation learning may not be obvious. The solution may also be biased and may require extensive tuning.
The followings are the hybrid objective for the policy gradient methods and the Q-learning. We will show the equations just to demonstrate the concept for now.
Hybrid policy gradient

Hybrid Q-learning
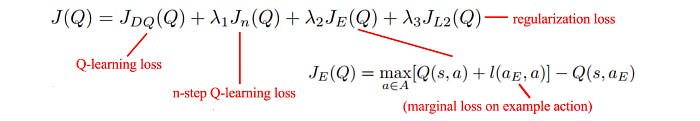
Thoughts
For imitation learning, we need to solve two major problems:
- how to collect expert demonstrations.
- how to optimize the policy for off-course situations.
The first problem may depend on complex methods like Guided Policy Search or trajectory optimization which we can have the system self-trained. For the second problem, we need to simulate those situations to collect new labels or use off-policy learning with the already collected samples.
Credits and reference
UC Berkeley Reinforcement Learning course: Imitation learning & advanced methods.
